金博宝app手机版 OpenAI联合五巨头刚进场, 中国团队的答卷依然上线


(文/陈济深裁剪/张广凯)
好意思东时期5月5日,OpenAI联合英伟达、AMD、英特尔、微软和博通,发布了一项名为MRC的新式收罗传输条约,标的是处治大界限AI集群中GPU之间的数据传输效用问题。
OpenAI在公告中提到,ChatGPT每周活跃用户依然打破9亿。用户界限络续推广,背后对应的是测验、推理和调遣系统的连续扩张。收罗运行从底层配套,变成影响GPU灵验产能的关节轨范。
现时,MRC依然部署在OpenAI最大界限的超算集群中,而五家配合股伴险些隐秘了好意思国AI芯片和云规画产业的一说念中枢力量。
5月21日,中国大模子独角兽智谱晓谕,联合清华大学与驭驯收罗,在GLM-5.1线上坐褥集群中完成了另一种全新收罗架构ZCube的界限化落地。
三个月前,智谱刚资格过一轮信得过的算力危险。2月12日GLM-5上线后,公共范围内的需求激增,并发拜访量打破了既有缱绻的上限,就业出现列队、反馈蔓延和卡顿。智谱屡次对国产芯片集群进行扩容,限量发售GLMCodingPlan套餐,仍然无法澈底处治供不应求的时势,不得不在2月16日发公告,面向芯片厂商和算力就业商公开启动「算力合推动说念主」招募磋议。
堆卡扩容是最径直的应付技能,但卡的供给有天花板。ZCube的落地,意味着智谱和配合股伴给出了另一种念念路:在现存GPU界限不变的前提下,从收罗架构层挖掘效用空间。
往常两年,AI算力竞赛的干线是拼GPU数目。万卡集群、十万卡集群,险些成了推断AI公司基础设施才略的硬方针。但OpenAI和智谱险些同期开释的信号标明,AI基建依然过问了一个新阶段:GPU以外,收罗运行成为超大界限AI基础设施的下一个主战场。
算力的守密瓶颈:GPU仍然不够,收罗更成了问题
大模子推理不是单张GPU的事。每处理一次用户苦求,集群里面齐要高频传递多数中间数据。
现时业界主流的作念法是PD分离部署,崇敬「斡旋问题」的GPU和崇敬「生成回复」的GPU分开部署在不同节点上,中间有一块叫KVCache的数据需要跨节点搬运,搬运量大且极不均匀。
传统的收罗架构很难适配这种不均匀的流量模式。少数几台交换机和链路反复拥挤,其他链路却莫得被充分诈欺。收尾即是,总带宽看起来够,但灵验朦拢上不去,GPU只可等数据。
智谱时刻团队作念过一组适度变量实验:一样的GPU和软件,仅将收罗带宽从100Gbps擢升到200Gbps,推理总朦拢就涨了约19%,首Token时延下落了约22%。
这阐发,现存集群里颠倒一部分GPU并莫得充分开释产能。卡没坏,但路运行成为决定灵验产能的关节变量。
业界沿用了二十多年的组网神志叫Clos架构。它的基本风物,是交换机一层一层往上堆,底层Leaf交换机连GPU,顶层Spine交换机崇敬转发跨组流量,幸运5星彩app官方手机版像金字塔。
英伟达在此基础上推过一个优化版ROFT,把相通编号的GPU接到归并台Leaf交换机上,测验场景下收尾可以。但到了PD分离推理场景,问题显现了。
KVCache传输自然是分歧称的,不同GPU、不同网卡承担的负载各别很大,ROFT假定的「均匀分派」不设立。少数几台Leaf交换机变成热门,PFC反压时时触发,链路拥塞进一步放大尾时延,拖慢统共这个词集群。
打个比喻,ROFT假定每条车说念上的车流量差未几,是以均匀分派红绿灯时长。现实上有几条说念车止境多,有几条说念险些没车,红绿灯决议就失效了。
推翻二十年旧架构:ZCube怎么破局
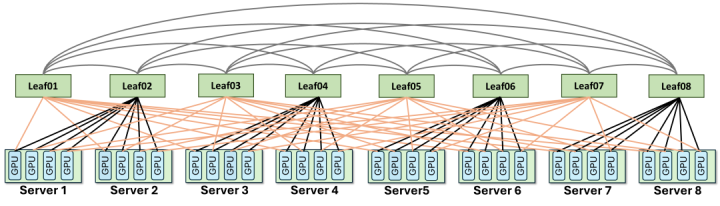
智谱、清华大学和驭驯收罗这次落地的决议ZCube,则是选拔把金字塔拍平。
这一拓扑架构此前已由清华大学、中关村实验室、驭驯收罗、字节进步等团队在ACMSIGCOMM2025论文中系统建议。SIGCOMM是规画机收罗领域公认的公共最高档别学术会议。据智谱露出,评审曾评价ZCube「显赫改变了统共这个词行业对收罗的知道神志」(significantlychangethewaywethinkaboutandunderstandnetworking)。
这次智谱将其引入GLM-5.1coding坐褥推理集群,是ZCube初次在信得过大界限推理环境中完成考证。
传统Clos架构的金字塔结构里,底层交换机连GPU,顶层交换机崇敬转发,数据跨组传输要先上楼再下楼,旅途长,也更容易形成局部拥塞。
ZCube的作念法是砍掉顶层,只留底层交换机,分红两组作念统共互联,金博宝app手机版再用一种搀和接入神志让每张GPU同期连合两组交换机。
最终收尾是,全网自便两张GPU之间只需历程两台交换机就能通讯,每对GPU之间齐唯惟一条最优旅途。由拓扑映射和旅途选拔形成的毋庸冲突,被大幅压低。
2026FIFA世界杯中国官网自然,这并不虞味着统共拥塞齐会灭亡。多个GPU同期向归并方针地写入数据这类不行幸免的拥塞仍然存在,但那需要拥塞适度和调遣计谋行止理,依然不是ZCube主要处治的问题。
因为砍掉了统共这个词顶层,ZCube还能径直减少交换机和光模块数目。按照智谱露出的数据,交换机与光模块成本开支减少约三分之一。
扩展性上,使用一层容量为51.2T的交换机,也即是128个400Gbps端口,ZCube就能构建一个连合16384块400Gbps网卡的收罗。要是使用更高容量的交换机,梗概将ZCube辞别为多个平面,界限可以进一步推到数万乃至数十万张GPU。
这套架构的适用范围也不啻推理,测验场景下一样灵验。
回到刚才的比喻:ZCube不是优化红绿灯,而是重新画路网,让正本由拓扑结构形成的毋庸冲突大幅减少。
智谱在一个千卡级的GLM-5.1coding推理集群上作念了实测。GPU型号、软件栈、业务代码一说念不动,只把收罗从ROFT换成ZCube。
据智谱露出,GPU平均推理朦拢擢升15%,TTFTP99,也即是首Token时延的99分位,镌汰40.6%,交换机与光模块成本减少三分之一。按万卡界限估算,仅收罗硬件一项可从简2.1亿至6.4亿元。
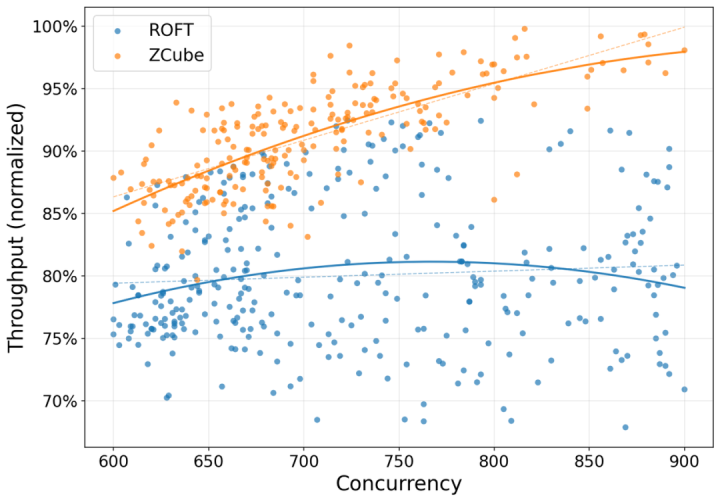
现时,该集群已在线上踏实运行超越两周,在GLM-5.1coding推理就业中阐述着紧迫作用。
ZCube的部署并非软件升级,而是物理纠正。布线决议、IP编址、路由计谋、交换机设立一说念要针对新架构重新设想。驭驯收罗团队为此开导了一套好意思满的自动化器用链,隐秘机房布局设想、连线正确性校验、设立自动生成与批量下发,这是短时期内完成大界限坐褥集群纠正的关节。
OpenAI走的是另一条路
OpenAI的MRC条约处治的亦然大界限集群的收罗瓶颈,但场景和阶梯齐不同。
MRC主要面向测验收罗,处治的是大界限GPU集群作念同步预测验时,尾部蔓延和链路故障拖慢统共这个词测验功课的问题。ZCube这次落地在推理收罗,拼凑的是PD分离场景下KVCache传输形成的结构性拥塞。
归并类瓶颈,在测验和推理两头各有各的发达风物。
时刻阶梯上,MRC莫得像ZCube那样重构拓扑,而是在现存多平面两层以太网结构上,通过多旅途并发传输和智能路由把旅途诈欺率拉高,哪条路堵了就微秒级绕过。
MRC依然部署在OpenAI一说念最大界限的英伟达GB200超算集群上,并已用于测验多个前沿模子。条约轨范则通过OpenComputeProject向全行业绽开。
两种决议致使不互斥,表面上可以重复。但它们在归并个月被推到产业台前这件事自己,比单项时刻更值得暖和:GPU武备竞赛打了两年之后,中好意思双方齐运行在收罗层伊始了。
OpenAI手执五家好意思国芯片和云巨头的全产业链撑持,选拔在现存架构上作念条约层优化;智谱联合清华和驭驯收罗走产学研旅途,径直从架构层重新设想。
两条路各自处治各自的问题,但共同指向一个判断:往常比的是谁能拿到更多卡,现时运行比谁能把已有卡组织得更灵验率。
AI基建迎来效用时间
要是说OpenAI和智谱的共同点,是把收罗推到AI基建台前,那么两家公司面临的资源禁止其实统共不同。
本年5月,黄仁勋搭上特朗普的「空军一号」再度访华,英伟达在中国阛阓的姿态看上去比以往任何时候齐积极。但姿态归姿态,H100和GB200仍受严格达成;H200诚然出现了一定松动,能否形成踏实、界限化的供给仍充满不笃定性。
与此同期,国产算力正在快速补位。
智谱在2月发布算力合推动说念主磋议时,明确提到已「屡次对国产芯片集群进行扩容」。GLM-5自己也已完成与华为昇腾、寒武纪、摩尔线程等多家国产芯片平台的推理适配。
中国AI公司手里的牌,依然从单一的英伟达GPU,变成了国产芯片与存量英伟达芯片搀和的多元组合。
ZCube的价值正值在这里:它处治的是收罗层的效用问题,并不绑定特定GPU家具和生态。无论集群里跑的是昇腾、寒武纪如故英伟达,只须界限上千卡、走PD分离推理,收罗拥塞的瓶颈就客不雅存在。
ZCube省却的三分之一交换机和光模块成本,在万卡界限下是2亿到6亿元级别的真金白银。更紧迫的是,这类架构优化并不依赖恭候下一代GPU供给放开,而是从现存系统里径直挖效用。
ZCube还莫得走出智谱成为行业通用决议,但论文、坐褥数据和自动化部署器用链依然把一件事阐发晰了:收罗架构优化不仅仅实验室里的拓扑设想,而是可以径直过问坐褥集群、改革为朦拢和成本收益的工程才略。
当公共AI基建从单纯堆卡过问系统效用时间金博宝app手机版,这种从架构层向内挖潜的才略,正在成为中国AI产业的一张新牌。